课设
css3
QLC
多线程
redis
知识蒸馏
云编程
matlab入门案例
负载均衡
网络攻击模型
记事本
硬件
UGUI
如何修复网站漏洞
绝对路径和相对路径
银行家算法
EDM营销
filter
应力强度因子
自定义Starter案例实操
数据科学
2024/4/12 1:01:28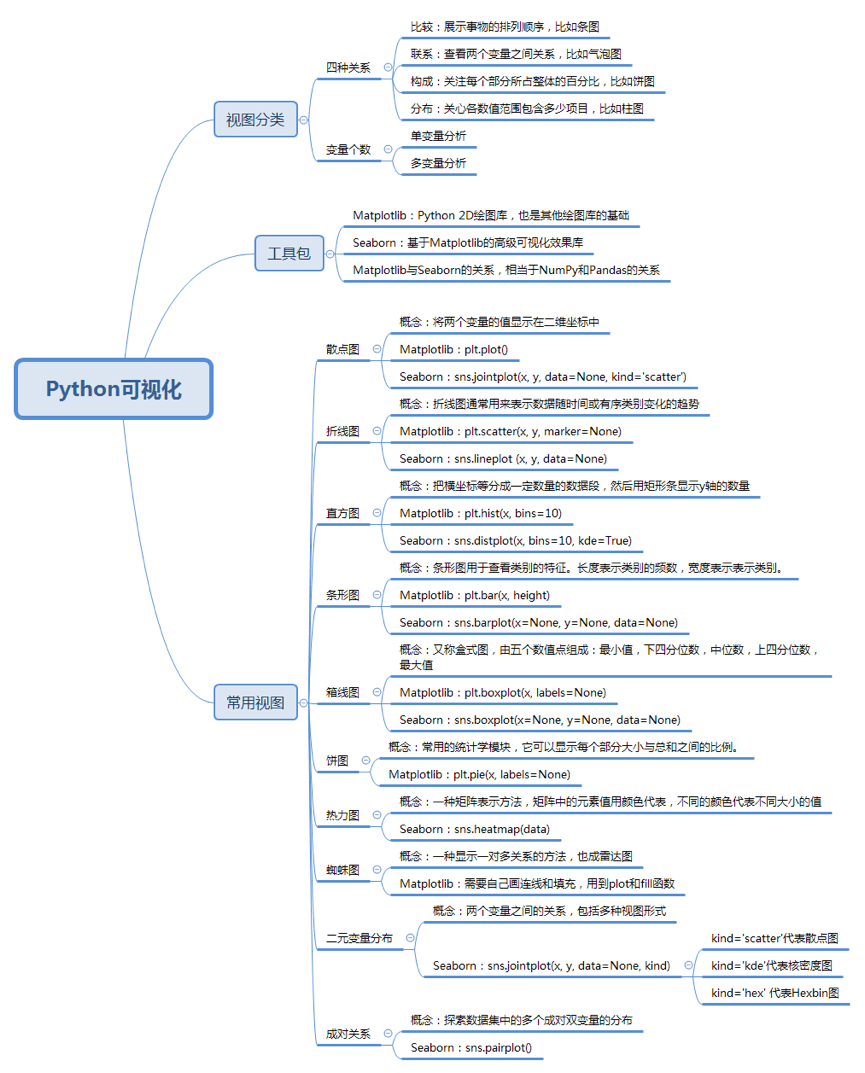
一次学会Python数据可视化的10种技能
一次学会Python数据可视化的10种技能 如果你想要用Python进行数据分析,就需要在项目初期开始进行探索性的数据分析,这样方便你对数据有一定的了解。其中最直观的就是采用数据可视化技术,这样,数据不仅一目了然,而且更容…
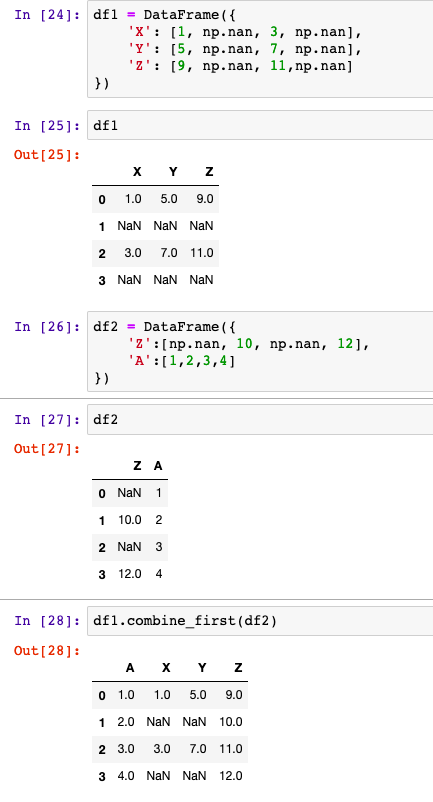
Pandas玩转数据
Pandas玩转数据
一、排序功能
0x1 Series的排序
s1 Series(np.random.randn(10))
s2 s1.sort_values(ascendingFalse) # 按照值降序排列
s2.sort_index() # 按照索引升序排列0x2 Dataframe的排序
df1 DataFrame(np.random.randn(40).reshape(8,5), columns[A,B,C,…

机器学习笔记 - 在表格数据上应用高斯混合GMM和网格搜索GridSearchCV提高分类精度的机器学习案例
1、需求及数据集说明 这是一项二分类任务,评估的是分类准确性(正确预测的标签百分比)。训练集有1000个样本,测试集有9000个样本。你的预测应该是一个9000 x 1的向量。您还需要一个Id列(1到9000),并且应该包括一个标题。格式如下所示:
Id,Solution
1,0
2,1
3,1
...
900…
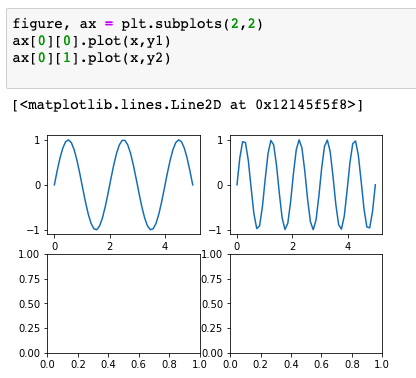
Subplot和Subplots绘制子图
Subplot和Subplots绘制子图
plot可以绘出精美的图形,但是如果想要在一张图中展示多个子图,plot就很难办了。
matplotlib提供了subplot来解决这一问题。(其实很像matlab中的绘图方法)
Subplot绘图方法
首先利用之前plot的方法&…
Python数据科学常用库——Pandas
Python数据科学常用库——Pandas
一、数据格式Series
0x1 创建Series
import numpy as np
import pandas as pds1 pd.Series([1,2,3,4]) # 通过Python list创建s2 pd.Series(np.arange(10)) # 通过numpy array创建s3 pd.Series({1:1,2:2}) # 通过字典创建s4 Seri…
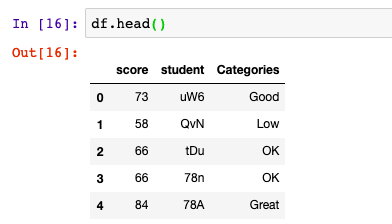
数据分箱技术Binning
数据分箱技术Binning 数据分箱就是按照某种规则将数据进行分类。就像可以将水果按照大小进行分类,售卖不同的价格一样。 对Series进行分箱
创建一个整形随机的series,表示学生的成绩:
import numpy as np
import pandas as pd
from pandas …
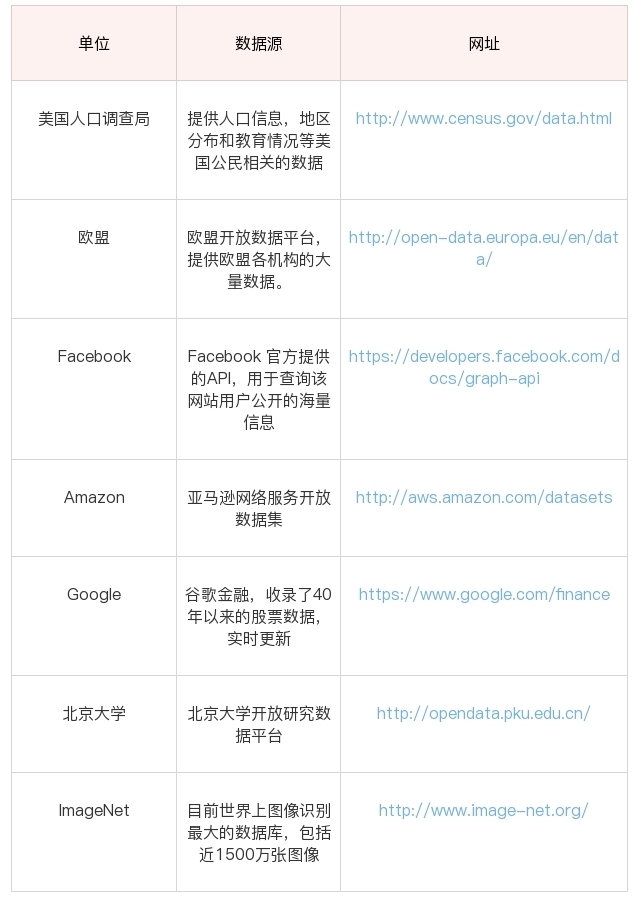
数据采集:如何自动化采集数据?
上一节中我们讲了如何对用户画像建模,而建模之前我们都要进行数据采集。数据采集是数据挖掘的基础,没有数据,挖掘也没有意义。很多时候,我们拥有多少数据源,多少数据量,以及数据质量如何,将决定…
学数据分析要掌握哪些基本概念?
学数据分析要掌握哪些基本概念? 美国明尼苏达州一家Target百货被客户投诉,这名客户指控Target将婴儿产品优惠券寄给他的女儿,而他女儿还是一名高中生。但没多久这名客户就来电道歉,因为女儿经他逼问后坦承自己真的怀孕了。
Targe…
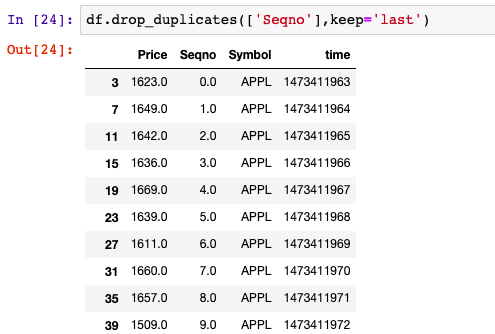
通过去重进行数据清洗
通过去重进行数据清洗
数据初始 Seqno列去重
查看Seqno列都有哪些值
df[Seqno].unique() # 查看唯一的值duplicated方法 duplicated用于从上到下比较指定某一列的值,当这个值第一次出现时,返回False,当这个值和上一个比一样时,…

Python科学计算:Pandas
今天我来给你介绍Python的另一个工具Pandas。
在数据分析工作中,Pandas的使用频率是很高的,一方面是因为Pandas提供的基础数据结构DataFrame与json的契合度很高,转换起来就很方便。另一方面,如果我们日常的数据清理工作不是很复杂…
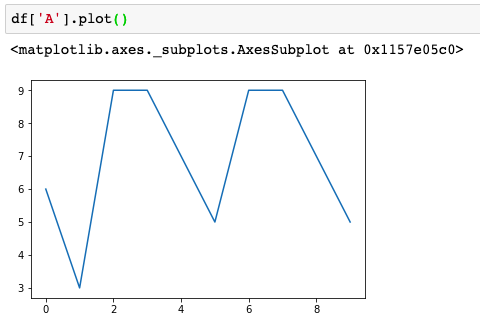
Pandas绘图之Series和Dataframe
Pandas绘图之Series和Dataframe
一、Series绘图
0x1生成数据并画图
首先生成一个series数据:
import numpy as np
import pandas as pd
from pandas import Series
import matplotlib.pyplot as plt
s1 Series(np.random.randn(10)).cumsum()直接绘制s1的图像&…
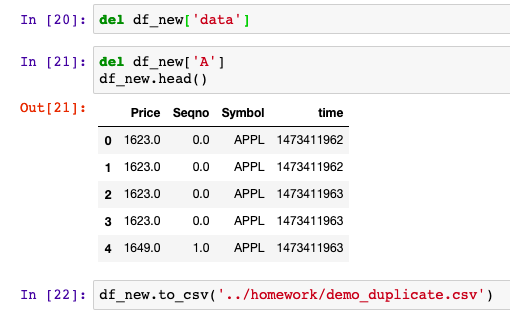
Apply函数进行数据预处理
Apply函数进行数据预处理
测试数据集: 包含两列:时间戳和字符串,大小为近8000行
在df中添加一列,使其全部都是a
将A列改的值为大写
df[A] df[A].apply(str.upper)使用apply进行预处理 将data数据拆分为三列
Apply接收一个…
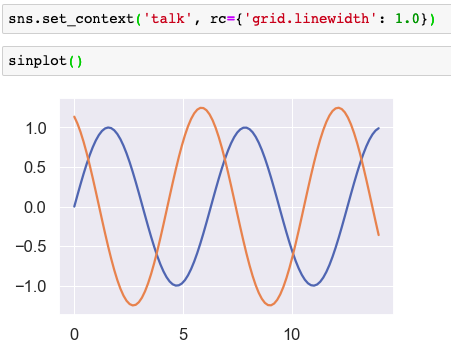
Seaborn设置图形显示的效果
Seaborn设置图形显示的效果
绘制三角函数
x np.linspace(0,14,100)
y1 np.sin(x)
y2 np.sin(x2)*1.25def sinplot()plt.plot(x,y1)plt.plot(x,y2)plt.show()使用matplotlib绘图的效果 使用seaborn绘图 设置显示主题
seaborn提供可绘图的5种风格主题:’darkgri…

《PySpark大数据分析实战》-07.Spark本地模式安装
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-04.了解Spark
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

释放数据价值这道难题,数据科学基础平台有解
去年底,《中共中央、国务院关于构建数据基础制度更好发挥数据要素作用的意见》(以下简称:" 数据二十条 ")正式颁布,标志着数据基础制度的建设步入快车道,数据要素化有望全面提速。
" 数据二…

《PySpark大数据分析实战》-27.数据可视化图表Pyecharts介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
创建简单的 Docker 数据科学映像
推荐:使用NSDT场景编辑器快速搭建3D应用场景
为什么选择 Docker for Data Science?
作为一名数据科学家,拥有一个标准化的便携式分析和建模环境至关重要。Docker 提供了一种创建可重用和可共享的数据科学环境的绝佳方法。在本文中ÿ…
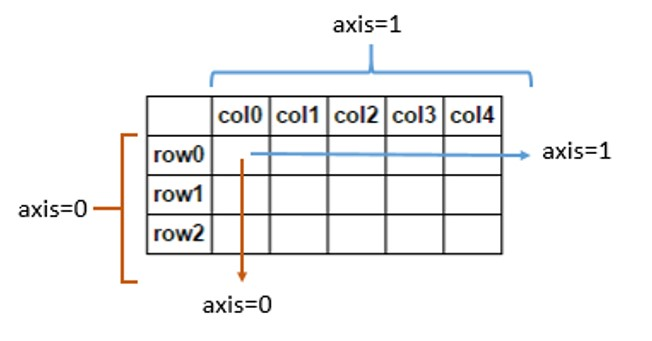
NumPy(axis=0 与axis=1)的区分
NumPy(axis0 与axis1)的区分
df pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],
columns["col1", "col2", "col3", "col4"])df.mean(axis1) 当执行下面代码后,删掉的却是一列&#x…
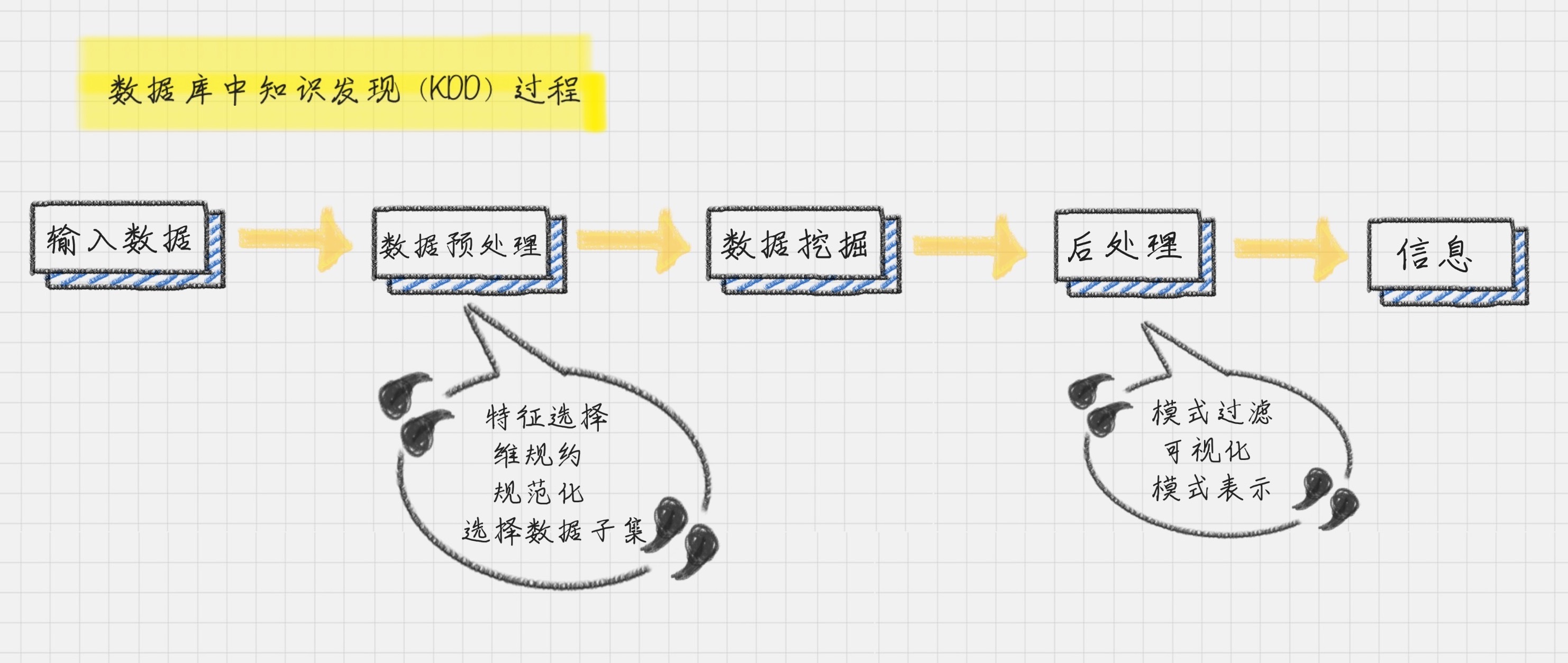
学习数据挖掘的最佳路径是什么?
上一节中,我给你分享了数据分析的全景图,其中最关键的部分就是数据挖掘,那什么是数据挖掘呢?
想象一下,茫茫的大海上,孤零零地屹立着钻井,想要从大海中开采出宝贵的石油。
对于普通人来说&…
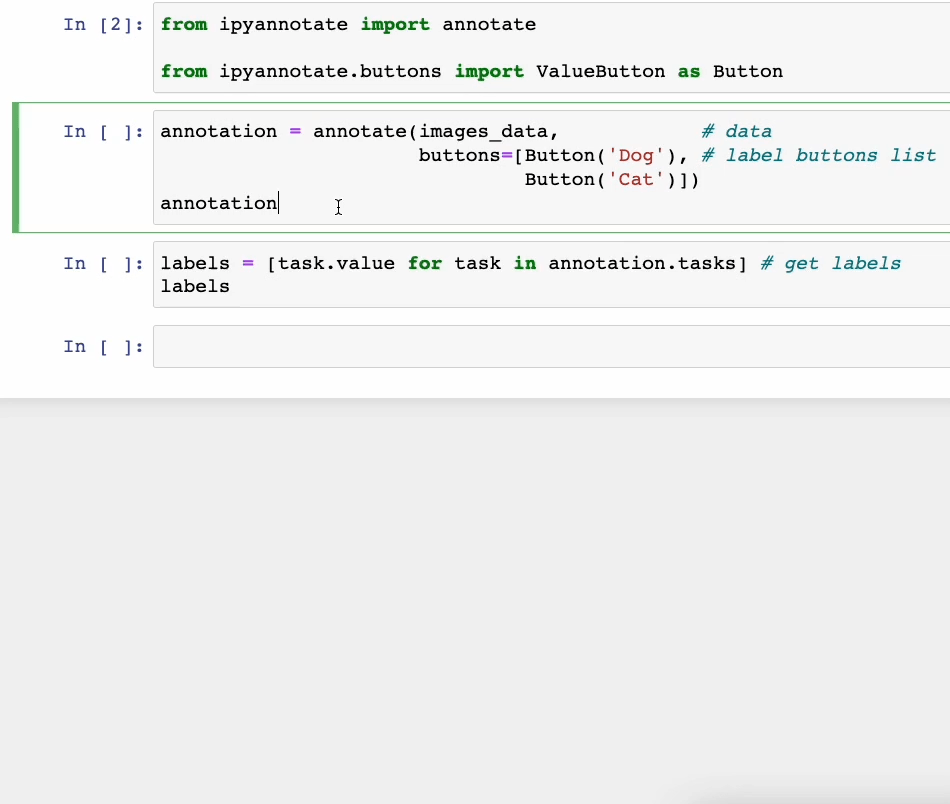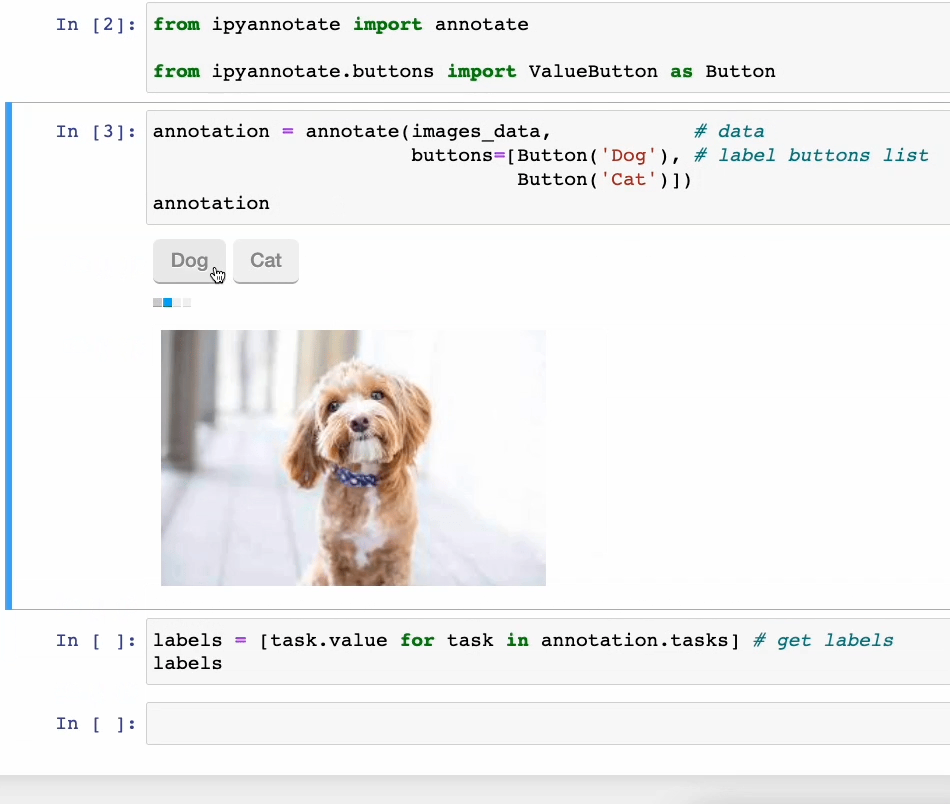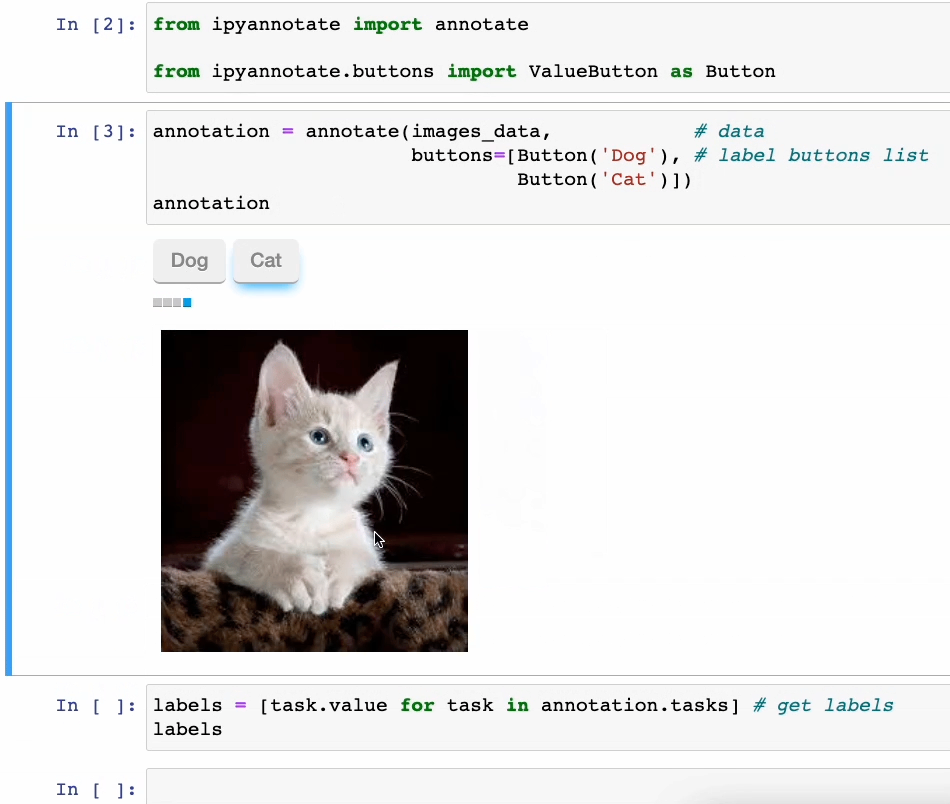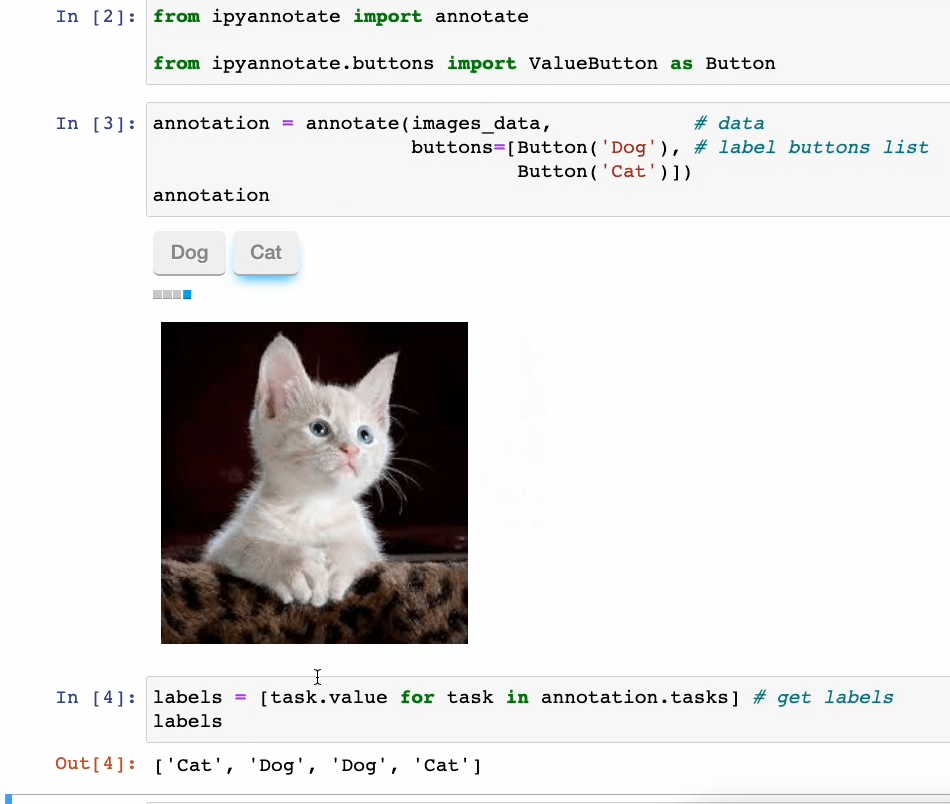
功能真强大!5个令人惊叹的 Jupyter 黑科技
Jupyter 是一种功能强大的交互式计算环境,被广泛应用于数据分析、机器学习、科学计算等领域。
除了常见的基本功能外,Jupyter还隐藏着许多令人惊叹的黑科技,这些功能可以帮助用户更高效地完成工作,提升工作体验。
在本文中&…

迅速收藏!109个数据科学面试问答,你绝对不能错过的宝藏库!
不管你是拥有上万经验条的“老手”,亦或是初出茅庐却天资过人的“新手”,面试官总能“难倒你”。
在面试的时候,面试官所出题目涉及的范围可能会非常广,这既考验了面试者的技能知识,又很能体现面试者的沟通技巧。面试…

《PySpark大数据分析实战》-14.云服务模式Databricks介绍基本概念
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
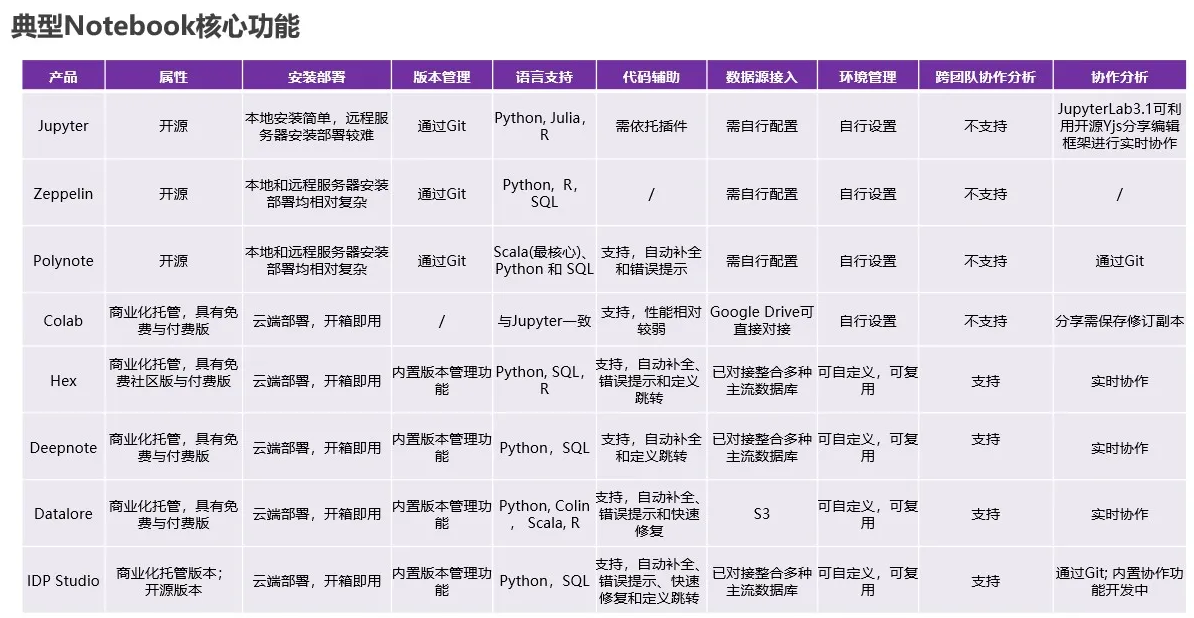
一文了解数据科学Notebook
编者按: 主要介绍什么是Notebook,Notebook在数据科学领域的应用的重要性与优势,以及数据科学家/算法团队在选择Notebook时需考虑哪些关键因素。同时,基于Notebook的筛选考量维度,对常见的Notebook进初步对比分析&#…

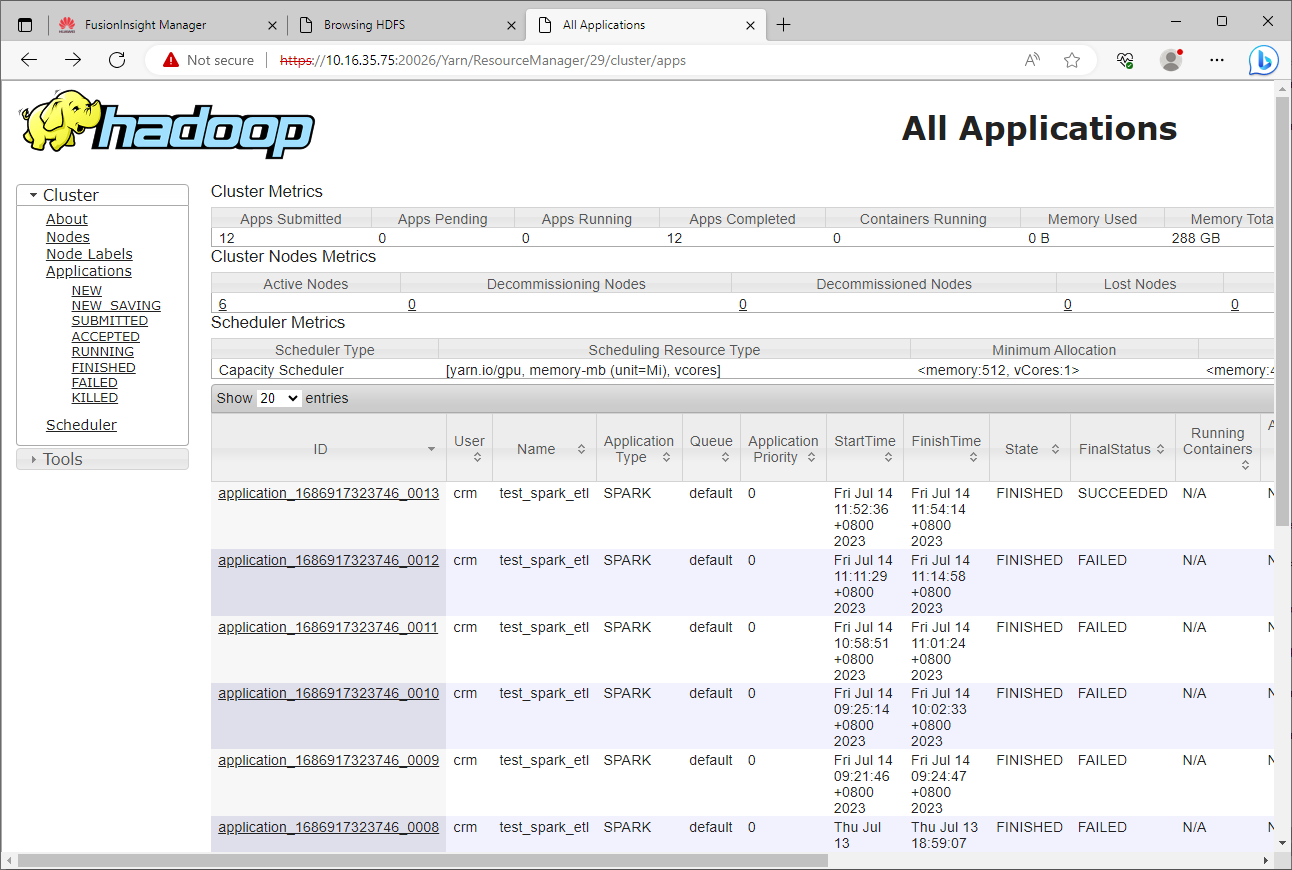
【FusionInsight 问题】FusionInsight HD 6.5.1 集群中遇到的问题(01)
FusionInsight HD 6.5.1 集群中遇到的问题(01) FusionInsight HD 6.5.1 集群中遇到的问题(01)Spark-on-HBase认证问题Failed to find any Kerberos tgt服务端配置修改客户端配置修改 Spark-on-HBase依赖包问题phoenix-core-4.13.1…

数据科学低代码工具思考2—现状分析
数据科学工具伴随着计算机技术的发展也在持续的演进。数据库、大数据以及人工智能等时代标志性技术的出现,对数据科学工具的能力也有了更高的要求。一般而言,工具发展的趋势都是首先会出现一个能够支持数据科学计算的开发框架,方便用户能够更…
数据的标准化和归一化
前面我们已经学习了识别数据缺失值已经对缺失值进行处理的方法,但是KNN的准确率都不是很高,今天我们继续进行数据探索进一步增强机器学习流水线;
通过数据直方图可以看到数据中的列的均值、最大值、最小值等差别很大;
from skle…
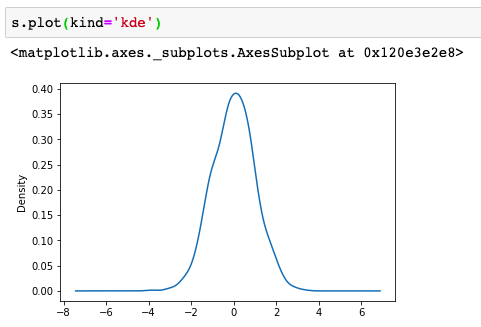
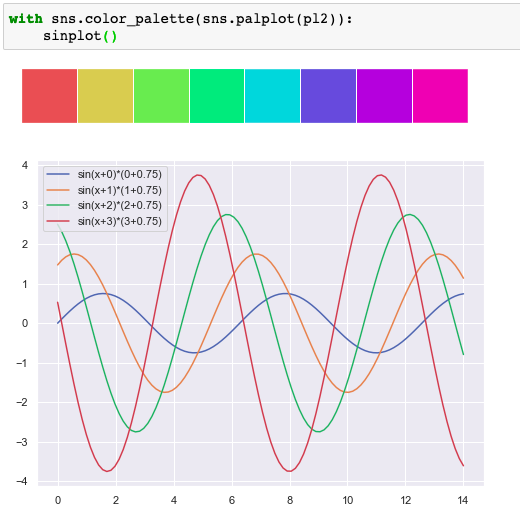
Seaborn强大的调色功能
Seaborn强大的调色功能
使用matplotlib绘图
def sinplot():x np.linspace(0,14,100)plt.figure(figsize(8,6))for i in range(4):plt.plot(x, np.sin(xi)*(i0.75), labelsin(x%s)*(%s0.75)% (i,i))plt.legend()sinplot()plt.figure(figsize(8,6))指定了图像大小为8*6 现在整…

Python基础语法:开始你的Python之旅
Python基础语法:开始你的Python之旅 上一节课我跟你分享了数据挖掘的最佳学习路径,相信你对接下来的学习已经心中有数了。今天我们继续预习课,我会用三篇文章,分别对Python的基础语法、NumPy和Pandas进行讲解,带你快速…
数据分析全景图及修炼指南
数据分析全景图及修炼指南
数据分析在现代社会中有重要地位。掌握数据,就是掌握规律。当你了解了市场数据,对它进行分析,就可以得到市场规律。当你掌握了产品自身的数据,对它进行分析,就可以了解产品的用户来源、用户…
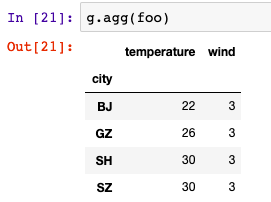
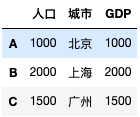
数据分组技术GroupBy
数据分组技术GroupBy和数据聚合Aggregation
数据概览 其中包括四行:日期、城市、温度、风力。它的大小为20行。
按列分组
加入这里按照city这一列进行分组:
g df.groupby(df[city])得到一个DataFrameGroupBy 类型的对象: <pandas.cor…
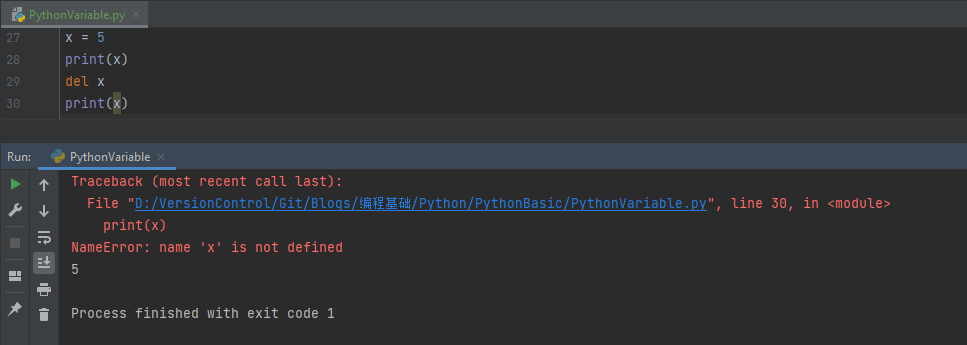
【编程基础之Python】9、Python中的变量
【编程基础之Python】9、Python中的变量Python中的变量变量的定义和赋值变量的命名规范变量的类型变量的作用域变量的赋值特殊的变量删除变量总结Python中的变量
在Python中,变量是用来存储数据的一种方式。Python是一种动态类型语言,因此在声明变量时不…

【编程基础之Python】1、初始Python
【编程基础之Python】1、初始Python初始Python什么是PythonPython的运行过程Python的应用领域如何学好Python初始Python
Python是一种跨平台的、开源免费的、解释型的、面向对象的高级编程语言。
Python的应用领域非常广泛,包括客户端程序、服务器程序、移动端程序…
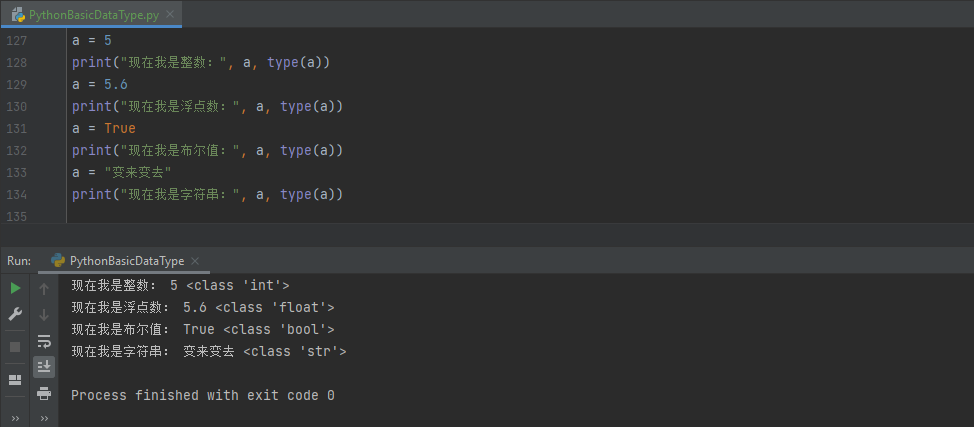
【编程基础之Python】7、Python基本数据类型
【编程基础之Python】7、Python基本数据类型Python基本数据类型整数(int)基本的四则运算位运算比较运算运算优先级浮点数(float)布尔值(bool)字符串(str)Python数据类型变换隐式类型…
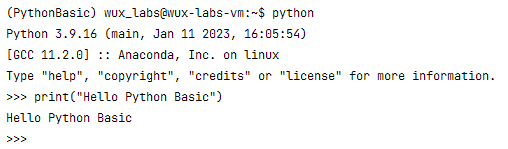
【编程基础之Python】3、创建Python虚拟环境
【编程基础之Python】3、创建Python虚拟环境创建Python虚拟环境为什么需要虚拟环境Windows上的Anaconda创建虚拟环境conda 命令conda env 命令创建虚拟环境切换虚拟环境验证虚拟环境Linux上的Anaconda创建虚拟环境创建虚拟环境切换虚拟环境验证虚拟环境总结创建Python虚拟环境 …

了解自动化机器学习 AutoML
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 自动化机器学习(AutoML)概述
自动化机器学习(AutoML)旨在自动化机器学习模型的开发流程,通过简化或去除需要专业知识的复杂步骤,…

《PySpark大数据分析实战》-16.云服务模式Databricks介绍运行案例
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
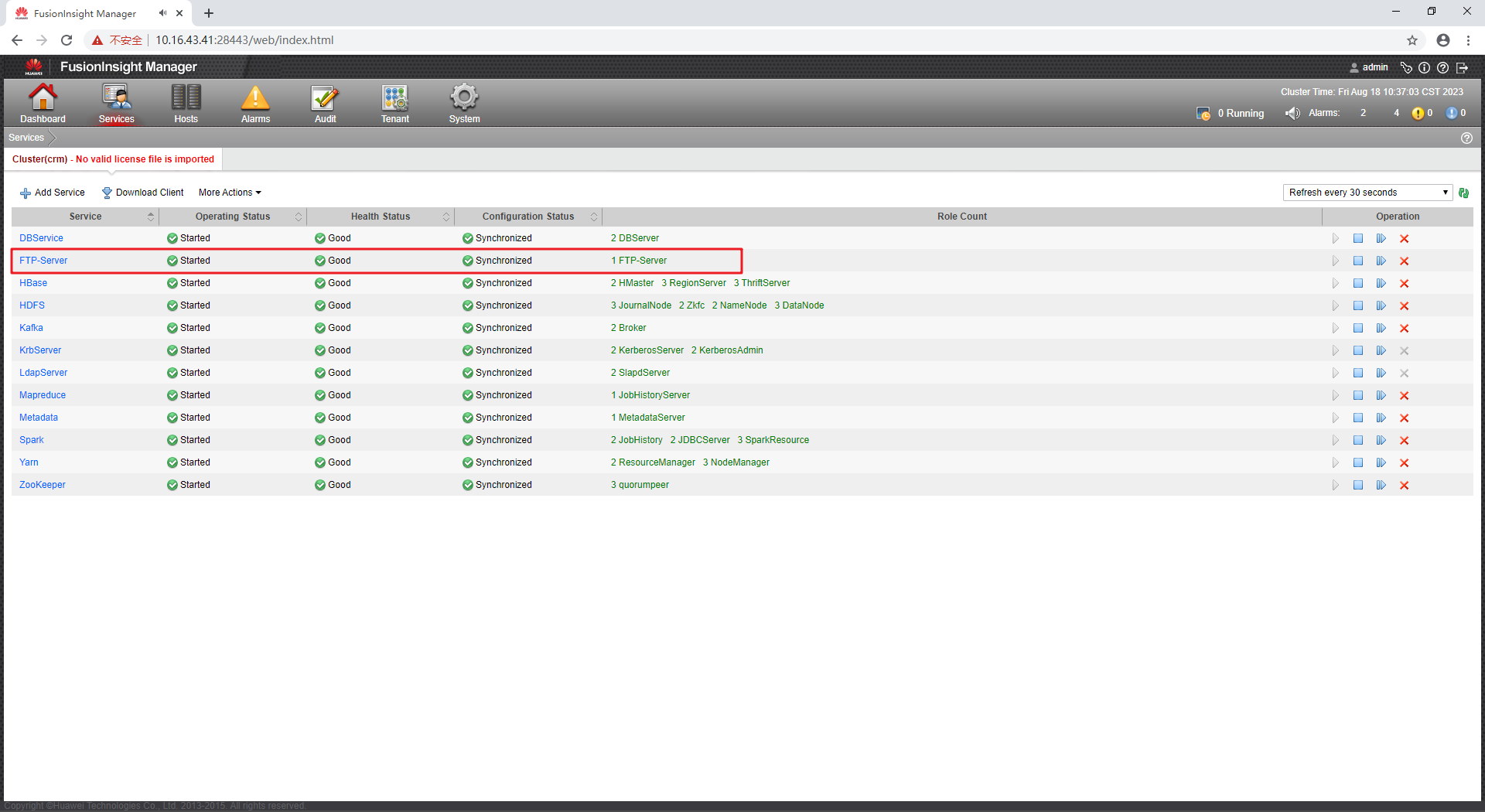
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server HBase从C50迁移到6.5.1(02)C50上准备FTP Server登录老集群FusionInsight C50的Manager准备FTP User准备FTP Server HBase从C50迁移到6.5.1(02&am…

《PySpark大数据分析实战》图书上线啦
《PySpark大数据分析实战》图书上线啦 《PySpark大数据分析实战》图书上线啦特殊的日子关于创作关于数据关于Spark关于PySpark关于图书/专栏 《PySpark大数据分析实战》图书上线啦
特殊的日子 不知不觉一转眼入驻CSDN已经满一年了,这真是一个充满意义的特殊的日子&…

从数据应用案例出发,探索2024年及未来的数据科学转型
如今,数据科学已经取得了长足的进步!回顾数据科学的发展史,19世纪,人们使用基本统计模型收集、存储和处理数据。后来,当计算机进入万千家庭,数字时代正式到来,并由此产生了大量数据。互联网上数…

并不止于表面理论和简单示例——《Python数据科学项目实战》
Python 现在可以说是运用最广泛的编程语言之一,使用 Python 的人不只局限在计算机相关专业的从业者,很多来自金融领域、医疗领域以及其他我们无法想象的领域的人,每天都在使用 Python处理各种数据、使用机器学习进行预测以及完成各种有趣的工作。 长久以来ÿ…
面试题---推荐系统
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统计学检验箱…

《PySpark大数据分析实战》-03.了解Hive
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
NumPy 入门教程
文章目录NumPy 入门教程安装数组创建与操作数组索引与切片数组运算多维数组的创建与操作数组的形状和大小数组的广播数组的复制和视图矩阵运算总结NumPy 入门教程
NumPy 是一个非常流行的 Python 数值计算库,它可以帮助我们处理向量、矩阵等数学对象,还…
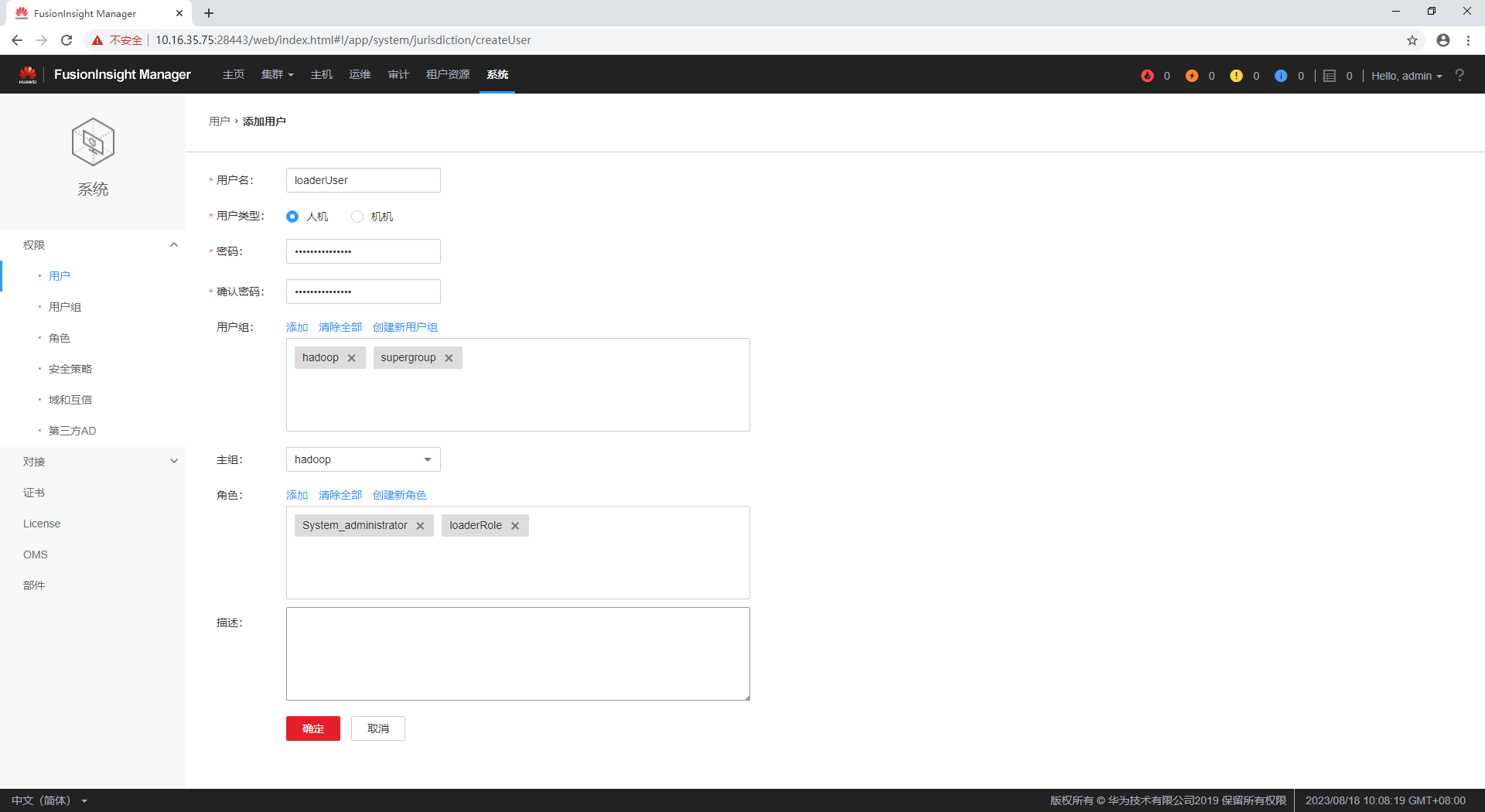
【FusionInsight 迁移】HBase从C50迁移到6.5.1(03)6.5.1上准备Loader
【FusionInsight 迁移】HBase从C50迁移到6.5.1(03)6.5.1上准备Loader HBase从C50迁移到6.5.1(03)6.5.1上准备Loader登录新集群FusionInsight 6.5.1的Manager准备Loader服务准备Loader Role准备Loader User HBase从C50迁移到6.5.1&…

《PySpark大数据分析实战》-26.数据可视化图表Seaborn介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
机器学习笔记 - 【机器学习案例】在表格数据上应用高斯混合模型GMM和网格搜索GridSearchCV提高分类精度
1、需求及数据集说明 这是一项二分类任务,评估的是分类准确性(正确预测的标签百分比)。训练集有1000个样本,测试集有9000个样本。你的预测应该是一个9000 x 1的向量。您还需要一个Id列(1到9000),并且应该包括一个标题。格式如下所示:
Id,Solution
1,0
2,1
3,1
...
900…
【阶段总结】《非结构化信息分析应用与实践(筹)》
《非结构化信息分析应用与实践(筹)》Part 1.知识储备一、机器学习
1.几种常见的有监督学习算法
2.几种常见的无监督学习算法
3.数据挖掘基础知识 30 问
二、神经网络与深度学习
1.MP神经网络模型(附实例代码讲解)
2.图解LST…
用户画像:标签化就是数据的抽象能力
王兴说过,我们已经进入到互联网的下半场。在上半场,也就是早期的互联网时代,你永远不知道在对面坐的是什么样的人。那个年代大部分人还是QQ的早期用户。在下半场,互联网公司已经不新鲜了,大部分公司已经互联网化。他们…
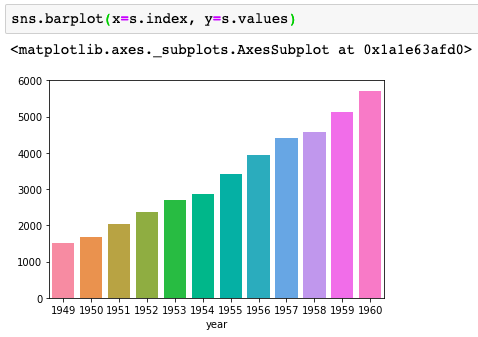
基于机器学习的库存需求预测 -- 机器学习项目基础篇(12)
在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
Pandas -此库有助于以2D阵列格式加载数据帧&#…
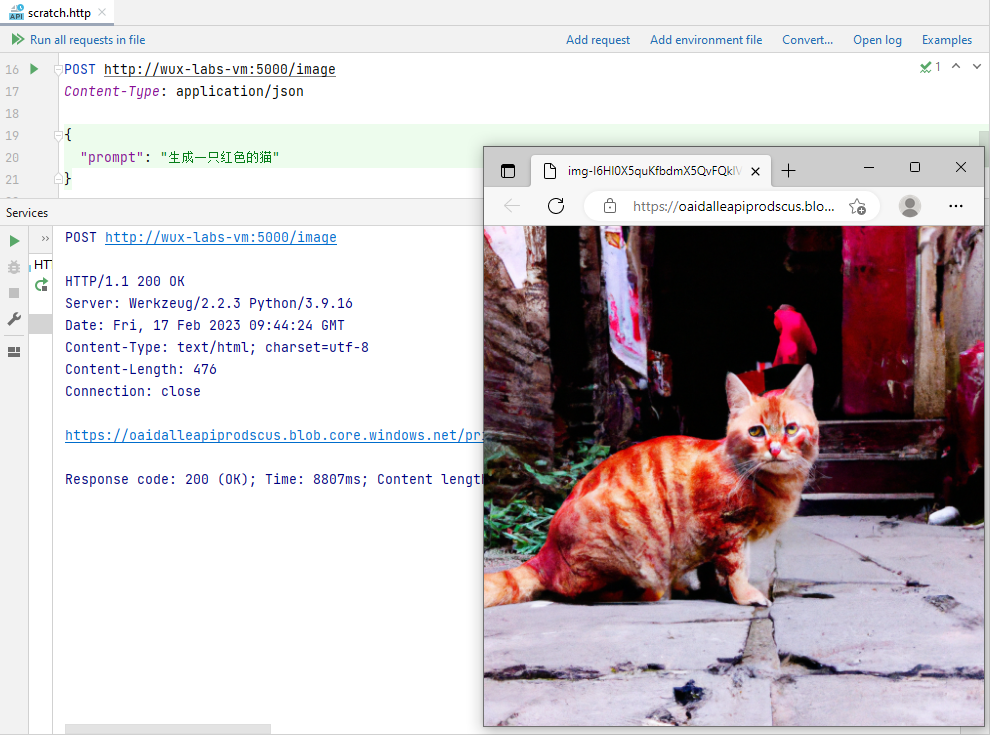
【初探人工智能】2、雏形开始长成
【初探人工智能】2、雏形开始长成【初探人工智能】2、雏形开始长成安装Flask封装Web接口雏形设置接收参数功能验证聊天写代码代码补全生成图片写在后面笔者初次接触人工智能领域,文章中错误的地方还望各位大佬指正! 【初探人工智能】2、雏形开始长成
在…
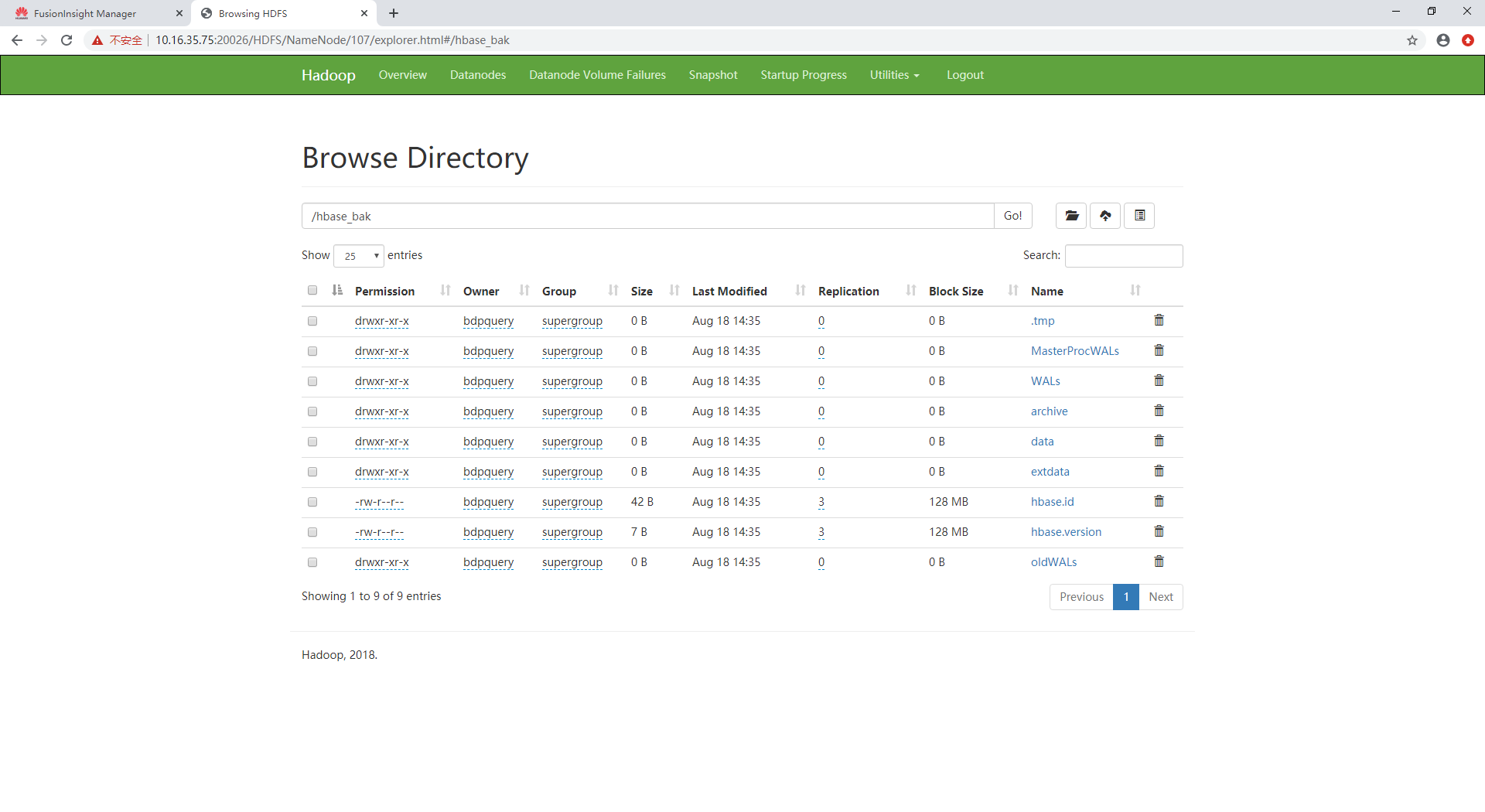
【FusionInsight 迁移】HBase从C50迁移到6.5.1(01)迁移概述
【FusionInsight 迁移】HBase从C50迁移到6.5.1(01)迁移概述 HBase从C50迁移到6.5.1(01)迁移概述迁移范围迁移前的准备HDFS文件检查确认HBase迁移目录确保数据落盘停止老集群HBase服务停止新集群HBase服务 HBase从C50迁移到6.5.1&a…
基于机器学习的假新闻检测 -- 机器学习项目基础篇(14)
不同平台上的假新闻正在广泛传播,这是一个令人严重关切的问题,因为它导致社会稳定和人们之间建立的纽带的永久破裂。很多研究已经开始关注假新闻的分类。 在这里,我们将尝试在Python中的机器学习的帮助下解决这个问题。
主要步骤
导入库和数…

《PySpark大数据分析实战》-18.什么是数据分析
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-24.数据可视化图表介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
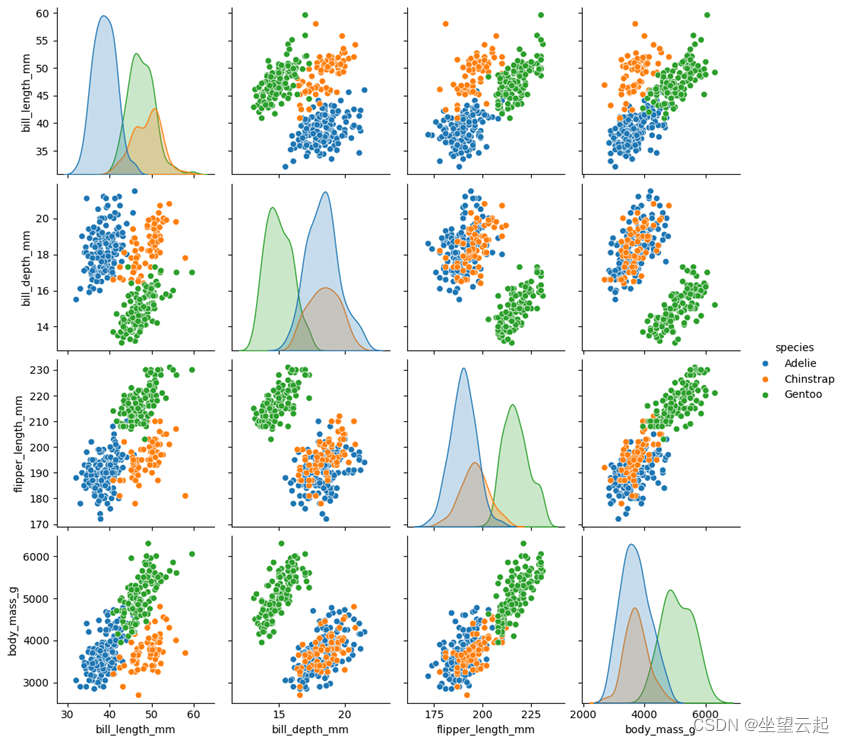
机器学习笔记 探索性数据分析(EDA) 中的配对图详述
一、介绍 在数据科学领域,理解和分析数据的第一步涉及全面的探索性数据分析(EDA)。这个过程对于识别模式、识别异常和建立假设至关重要。在 EDA 可用的众多工具中,配对图作为一种基本可视化技术脱颖而出,可提供多方面的数据视图。本文探讨了机器学习中的配对图,并解释了如…

【CheatSheet】Python、R、Julia数据科学编程极简入门
《Python、R、Julia数据科学编程极简入门》PDF版,是我和小伙伴一起整理的备忘清单,帮助大家10分钟快速入门数据科学编程。
另外,最近 TIOBE 公布了 2023 年 8 月的编程语言排行榜。
Julia 在本月榜单中实现历史性突破,成功跻身 …

以全新的视角审视重构——世界软件大师“鲍勃大叔”作序推荐
编程不只是写代码,更是一门艺术。编写优雅代码是一种极致追求,这需要一种极客精神才可以达到。高质量的代码不仅可以增加代码可读性,还可以确保所写的代码能够高质量运行和高效维护。 编程也是一门沟通语言,是团队沟通的方式。对代…

《PySpark大数据分析实战》-09.Spark独立集群安装
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-15.云服务模式Databricks介绍创建集群
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
什么是大数据?什么是数据科学
什么是大数据 大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。大数据技术,是指从各种各样类型的数据中,快速获得有价值信息的能力。适用于大数据的技术,包括大规模并行处理(MPP)数…
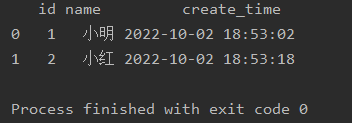
Pandas数据库大揭秘:read_sql、to_sql 参数详解与实战篇【第81篇—Pandas数据库】
Pandas数据库大揭秘:read_sql、to_sql 参数详解与实战篇
Pandas是Python中一流的数据处理库,而数据库则是数据存储和管理的核心。将两者结合使用,可以方便地实现数据的导入、导出和分析。本文将深入探讨Pandas中用于与数据库交互的两个关键方…

《PySpark大数据分析实战》-02.了解Hadoop
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

Python机器学习入门必学必会:机器学习与Python基础
1.机器学习常见的基础概念
根据输入数据是否具有“响应变量”信息,机器学习被分为“监督式学习”和“非监督式学习”。“监督式学习”即输入数据中即有X变量,也有y变量,特色在于使用“特征(X变量)”来预测“响应变量&…
介绍 Gradio 与 Hugging Face
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 我们可以使用 Gradio 库为我们的模型构建演示。Gradio 允许您完全使用 Python 为任何机器学习模型构建、自定义和共享基于 Web 的演示。使机器学习模型变得可交互和易于使用。
为什么首先要为您的机器…
《PySpark大数据分析实战》-01.关于数据
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
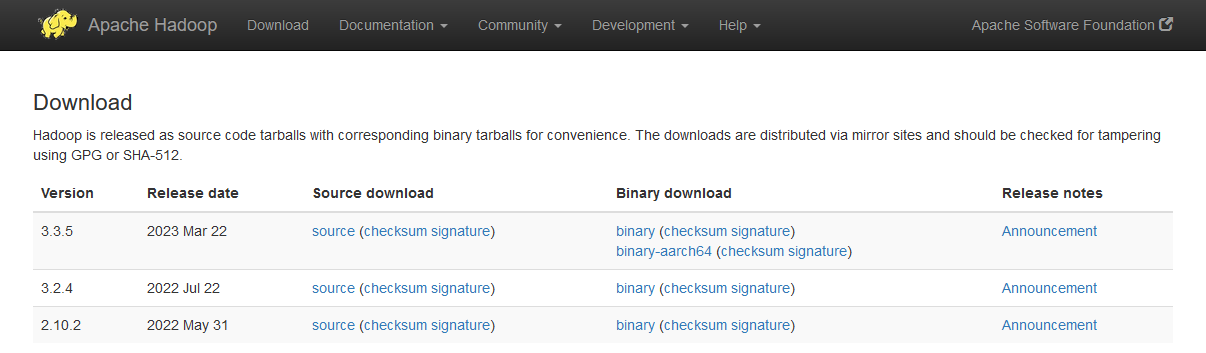
《PySpark大数据分析实战》-06.安装环境准备
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
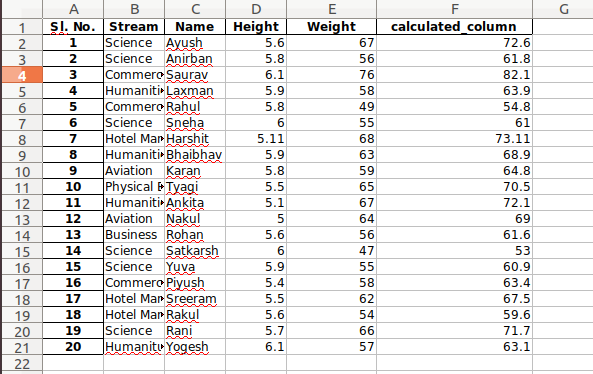
使用Pandas处理Excel文件
Excel工作表是非常本能和用户友好的,这使得它们非常适合操作大型数据集,即使是技术人员也不例外。如果您正在寻找学习使用Python在Excel文件中操作和自动化内容的地方,请不要再找了。你来对地方了。 在本文中,您将学习如何使用Pan…

《PySpark大数据分析实战》-25.数据可视化图表Matplotlib介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
数据科学低代码工具思考--工具起源
“数据科学低代码”由“数据科学”“低代码”两部分组成。这意味着我们将主要讨论“低代码”在“数据科学”应用场景中的使用。这将有别于现在流行的以“低代码”方式构建应用程序的讨论。但无论何种“低代码”,其核心都是为了降本增效。其是否能推广普及则主要依赖…

Python基础知识:Python函数中的形式参数和实际参数
函数参数包括形式参数和实际参数,简称形参和实参。其中形式参数即是在定义函数时函数后面括号中的参数列表(parameterlist),比如上一个帖子的示例中的width, length;实际参数则是调用函数时函数后面括号中的参数值&…
数据科学中常用的应用统计知识
随着大数据算法技术发展,数据算法越来越倾向机器学习和深度学习相关的算法技术,概率论和应用统计 等传统的技术貌似用的并不是很多了,但实则不然,在数据科学工作,还是会经常需要应用统计概率相关知识解决一些数据问题&…
遇到大数据行业的职业发展瓶颈,你有勇气去突破?
大数据行业的发展不是一直呈现指数增长的,而且作为身在其中的大数据行业从业者,大家或快或慢的都会遇到职业瓶颈,今天我们就聊聊数据人才的瓶颈有哪些,该如何去突破。 每个人在不同的成长阶段都会遇到瓶颈,就拿我自己来…